KT AIVLE/Daily Review
240913
bestone888
2024. 9. 14. 19:50
240913
데이터 프레임 조회
In [13]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
In [16]:
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/tips.csv'
tip = pd.read_csv(path)
tip
Out[16]:
total_billtipsexsmokerdaytimesize01234...239240241242243
| 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
| ... | ... | ... | ... | ... | ... | ... |
| 29.03 | 5.92 | Male | No | Sat | Dinner | 3 |
| 27.18 | 2.00 | Female | Yes | Sat | Dinner | 2 |
| 22.67 | 2.00 | Male | Yes | Sat | Dinner | 2 |
| 17.82 | 1.75 | Male | No | Sat | Dinner | 2 |
| 18.78 | 3.00 | Female | No | Thur | Dinner | 2 |
244 rows × 7 columns
In [22]:
print(tip.shape) # n 행 m 열
print(tip.size) # n*m
print(tip.info()) # 열 이름, 자료 개수, 자료형
print(tip.describe()) #통계
(244, 7)
1708
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 244 entries, 0 to 243
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 total_bill 244 non-null float64
1 tip 244 non-null float64
2 sex 244 non-null object
3 smoker 244 non-null object
4 day 244 non-null object
5 time 244 non-null object
6 size 244 non-null int64
dtypes: float64(2), int64(1), object(4)
memory usage: 13.5+ KB
None
total_bill tip size
count 244.000000 244.000000 244.000000
mean 19.785943 2.998279 2.569672
std 8.902412 1.383638 0.951100
min 3.070000 1.000000 1.000000
25% 13.347500 2.000000 2.000000
50% 17.795000 2.900000 2.000000
75% 24.127500 3.562500 3.000000
max 50.810000 10.000000 6.000000
loc() : 행 열 입력해 조회
In [34]:
# total_bill 조회
tip.loc[:, ['total_bill']]
Out[34]:
total_bill01234...239240241242243
| 16.99 |
| 10.34 |
| 21.01 |
| 23.68 |
| 24.59 |
| ... |
| 29.03 |
| 27.18 |
| 22.67 |
| 17.82 |
| 18.78 |
244 rows × 1 columns
In [38]:
tip[['total_bill']]
Out[38]:
total_bill01234...239240241242243
| 16.99 |
| 10.34 |
| 21.01 |
| 23.68 |
| 24.59 |
| ... |
| 29.03 |
| 27.18 |
| 22.67 |
| 17.82 |
| 18.78 |
244 rows × 1 columns
In [42]:
# tip, total_bill 조회
tip[['tip', 'total_bill']]
Out[42]:
tiptotal_bill01234...239240241242243
| 1.01 | 16.99 |
| 1.66 | 10.34 |
| 3.50 | 21.01 |
| 3.31 | 23.68 |
| 3.61 | 24.59 |
| ... | ... |
| 5.92 | 29.03 |
| 2.00 | 27.18 |
| 2.00 | 22.67 |
| 1.75 | 17.82 |
| 3.00 | 18.78 |
244 rows × 2 columns
In [44]:
# sex 부터 size 까지 조회
tip.loc[:, 'sex': 'size']
Out[44]:
sexsmokerdaytimesize01234...239240241242243
| Female | No | Sun | Dinner | 2 |
| Male | No | Sun | Dinner | 3 |
| Male | No | Sun | Dinner | 3 |
| Male | No | Sun | Dinner | 2 |
| Female | No | Sun | Dinner | 4 |
| ... | ... | ... | ... | ... |
| Male | No | Sat | Dinner | 3 |
| Female | Yes | Sat | Dinner | 2 |
| Male | Yes | Sat | Dinner | 2 |
| Male | No | Sat | Dinner | 2 |
| Female | No | Thur | Dinner | 2 |
244 rows × 5 columns
sort_values() : 원하는 열 기준으로 정렬
In [57]:
# tip, day, time 열을 tip 기준으로 내림차순 정렬
tip_tip = tip.loc[:, ['tip', 'day', 'time']].sort_values(['tip'], ascending = False)
tip_tip
Out[57]:
tipdaytime1702122359141...02361116792
| 10.00 | Sat | Dinner |
| 9.00 | Sat | Dinner |
| 7.58 | Sat | Dinner |
| 6.73 | Sat | Dinner |
| 6.70 | Thur | Lunch |
| ... | ... | ... |
| 1.01 | Sun | Dinner |
| 1.00 | Sat | Dinner |
| 1.00 | Sat | Dinner |
| 1.00 | Sat | Dinner |
| 1.00 | Fri | Dinner |
244 rows × 3 columns
iloc() != loc()
In [74]:
tip.iloc[:, 0:2] # index 0~1 열
Out[74]:
total_billtip01234...239240241242243
| 16.99 | 1.01 |
| 10.34 | 1.66 |
| 21.01 | 3.50 |
| 23.68 | 3.31 |
| 24.59 | 3.61 |
| ... | ... |
| 29.03 | 5.92 |
| 27.18 | 2.00 |
| 22.67 | 2.00 |
| 17.82 | 1.75 |
| 18.78 | 3.00 |
244 rows × 2 columns
In [76]:
tip.iloc[5:15, :] # index 5행 ~14행
Out[76]:
total_billtipsexsmokerdaytimesize567891011121314
| 25.29 | 4.71 | Male | No | Sun | Dinner | 4 |
| 8.77 | 2.00 | Male | No | Sun | Dinner | 2 |
| 26.88 | 3.12 | Male | No | Sun | Dinner | 4 |
| 15.04 | 1.96 | Male | No | Sun | Dinner | 2 |
| 14.78 | 3.23 | Male | No | Sun | Dinner | 2 |
| 10.27 | 1.71 | Male | No | Sun | Dinner | 2 |
| 35.26 | 5.00 | Female | No | Sun | Dinner | 4 |
| 15.42 | 1.57 | Male | No | Sun | Dinner | 2 |
| 18.43 | 3.00 | Male | No | Sun | Dinner | 4 |
| 14.83 | 3.02 | Female | No | Sun | Dinner | 2 |
In [88]:
# df.loc
tip.loc[1:3, 'total_bill': 'day']
Out[88]:
total_billtipsexsmokerday123
| 10.34 | 1.66 | Male | No | Sun |
| 21.01 | 3.50 | Male | No | Sun |
| 23.68 | 3.31 | Male | No | Sun |
In [90]:
# df.iloc
tip.iloc[1:3, 1:4]
Out[90]:
tipsexsmoker12
| 1.66 | Male | No |
| 3.50 | Male | No |
데이터프레임 조건으로 조회
In [99]:
# tip이 6 이상인 행 조회
tip6 = tip.loc[tip['tip']>6.0]
tip6
Out[99]:
total_billtipsexsmokerdaytimesize2359141170183212214
| 39.42 | 7.58 | Male | No | Sat | Dinner | 4 |
| 48.27 | 6.73 | Male | No | Sat | Dinner | 4 |
| 34.30 | 6.70 | Male | No | Thur | Lunch | 6 |
| 50.81 | 10.00 | Male | Yes | Sat | Dinner | 3 |
| 23.17 | 6.50 | Male | Yes | Sun | Dinner | 4 |
| 48.33 | 9.00 | Male | No | Sat | Dinner | 4 |
| 28.17 | 6.50 | Female | Yes | Sat | Dinner | 3 |
In [121]:
# 그 중 total_bill 40 이상인 행 조회
ans = tip6[tip6['total_bill']>=40]
ans
# tip 내림차순으로 정렬, index 제거
ans = ans.sort_values(['tip'], ascending = False)
ans.reset_index(inplace = True, drop = True)
ans
Out[121]:
total_billtipsexsmokerdaytimesize012
| 50.81 | 10.00 | Male | Yes | Sat | Dinner | 3 |
| 48.33 | 9.00 | Male | No | Sat | Dinner | 4 |
| 48.27 | 6.73 | Male | No | Sat | Dinner | 4 |
isin(), between()
In [124]:
# day가 Sat 또는 Sun
tip.loc[tip['day'].isin(['Sat', 'Sun'])]
Out[124]:
total_billtipsexsmokerdaytimesize01234...238239240241242
| 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
| ... | ... | ... | ... | ... | ... | ... |
| 35.83 | 4.67 | Female | No | Sat | Dinner | 3 |
| 29.03 | 5.92 | Male | No | Sat | Dinner | 3 |
| 27.18 | 2.00 | Female | Yes | Sat | Dinner | 2 |
| 22.67 | 2.00 | Male | Yes | Sat | Dinner | 2 |
| 17.82 | 1.75 | Male | No | Sat | Dinner | 2 |
163 rows × 7 columns
In [126]:
tip.loc[(tip['day'] =='Sat') | (tip['day'] == 'Sun')]
Out[126]:
total_billtipsexsmokerdaytimesize01234...238239240241242
| 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
| ... | ... | ... | ... | ... | ... | ... |
| 35.83 | 4.67 | Female | No | Sat | Dinner | 3 |
| 29.03 | 5.92 | Male | No | Sat | Dinner | 3 |
| 27.18 | 2.00 | Female | Yes | Sat | Dinner | 2 |
| 22.67 | 2.00 | Male | Yes | Sat | Dinner | 2 |
| 17.82 | 1.75 | Male | No | Sat | Dinner | 2 |
163 rows × 7 columns
In [134]:
# 범위 지정 between
tip.loc[tip['size'].between(1,3)]
tip.sort_values('size', ascending = True) # size 오름차순 정렬
Out[134]:
total_billtipsexsmokerdaytimesize67822221110...155143156141125
| 3.07 | 1.00 | Female | Yes | Sat | Dinner | 1 |
| 10.07 | 1.83 | Female | No | Thur | Lunch | 1 |
| 8.58 | 1.92 | Male | Yes | Fri | Lunch | 1 |
| 7.25 | 1.00 | Female | No | Sat | Dinner | 1 |
| 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| ... | ... | ... | ... | ... | ... | ... |
| 29.85 | 5.14 | Female | No | Sun | Dinner | 5 |
| 27.05 | 5.00 | Female | No | Thur | Lunch | 6 |
| 48.17 | 5.00 | Male | No | Sun | Dinner | 6 |
| 34.30 | 6.70 | Male | No | Thur | Lunch | 6 |
| 29.80 | 4.20 | Female | No | Thur | Lunch | 6 |
244 rows × 7 columns
In [138]:
tip.loc[(tip['size']>=1) & (tip['size']<=3)]
Out[138]:
total_billtipsexsmokerdaytimesize01236...239240241242243
| 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 8.77 | 2.00 | Male | No | Sun | Dinner | 2 |
| ... | ... | ... | ... | ... | ... | ... |
| 29.03 | 5.92 | Male | No | Sat | Dinner | 3 |
| 27.18 | 2.00 | Female | Yes | Sat | Dinner | 2 |
| 22.67 | 2.00 | Male | Yes | Sat | Dinner | 2 |
| 17.82 | 1.75 | Male | No | Sat | Dinner | 2 |
| 18.78 | 3.00 | Female | No | Thur | Dinner | 2 |
198 rows × 7 columns
In [148]:
# 조넉네 맞는 하나의 열 조회
tip.loc[tip['size'] >= 5, ['size']]
Out[148]:
size125141142143155156185187216
| 6 |
| 6 |
| 5 |
| 6 |
| 5 |
| 6 |
| 5 |
| 5 |
| 5 |
In [160]:
tip5 = tip.loc[tip['size']>= 5, ['total_bill', 'tip', 'size']]
# total_bill 오름차순 정렬, 같으면 tip 내림차순 정렬
tip5.sort_values(['total_bill', 'tip'], ascending = [True, False])
Out[160]:
total_billtipsize185143216125155187141142156
| 20.69 | 5.00 | 5 |
| 27.05 | 5.00 | 6 |
| 28.15 | 3.00 | 5 |
| 29.80 | 4.20 | 6 |
| 29.85 | 5.14 | 5 |
| 30.46 | 2.00 | 5 |
| 34.30 | 6.70 | 6 |
| 41.19 | 5.00 | 5 |
| 48.17 | 5.00 | 6 |
reset_index() 인덱스 제거
- drop = True
- inplace = True
In [167]:
# tip이 6 이상
good = tip.loc[tip['tip']>=6]
good.reset_index(drop = True, inplace = True)
good
# index 제거
Out[167]:
total_billtipsexsmokerdaytimesize01234567
| 39.42 | 7.58 | Male | No | Sat | Dinner | 4 |
| 32.40 | 6.00 | Male | No | Sun | Dinner | 4 |
| 48.27 | 6.73 | Male | No | Sat | Dinner | 4 |
| 34.30 | 6.70 | Male | No | Thur | Lunch | 6 |
| 50.81 | 10.00 | Male | Yes | Sat | Dinner | 3 |
| 23.17 | 6.50 | Male | Yes | Sun | Dinner | 4 |
| 48.33 | 9.00 | Male | No | Sat | Dinner | 4 |
| 28.17 | 6.50 | Female | Yes | Sat | Dinner | 3 |
데이터 프레임 집계
In [176]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
In [178]:
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/tips.csv'
df = pd.read_csv(path)
df
Out[178]:
total_billtipsexsmokerdaytimesize01234...239240241242243
| 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
| ... | ... | ... | ... | ... | ... | ... |
| 29.03 | 5.92 | Male | No | Sat | Dinner | 3 |
| 27.18 | 2.00 | Female | Yes | Sat | Dinner | 2 |
| 22.67 | 2.00 | Male | Yes | Sat | Dinner | 2 |
| 17.82 | 1.75 | Male | No | Sat | Dinner | 2 |
| 18.78 | 3.00 | Female | No | Thur | Dinner | 2 |
244 rows × 7 columns
In [180]:
# total_bill, tip : 연속값
# sex, smoker, day, time, size : 범주값
- sum()
- max()
- min()
In [189]:
# sum() 기본적으로 axis = 0 기준
print(tip['total_bill'].sum())
print(tip['total_bill'].sum(axis = 0))
4827.77
4827.77
groupby()
In [200]:
# as_index = True
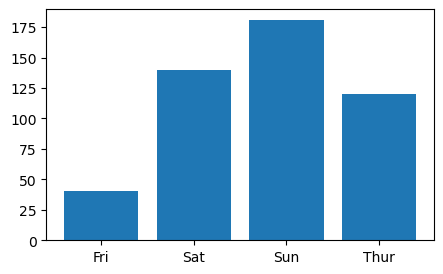
tip.groupby('day', as_index = True)[['tip']].sum()
Out[200]:
tipdayFriSatSunThur
| 51.96 |
| 260.40 |
| 247.39 |
| 171.83 |
In [202]:
# as_index = False
tip.groupby('day', as_index = False)[['tip']].sum()
Out[202]:
daytip0123
| Fri | 51.96 |
| Sat | 260.40 |
| Sun | 247.39 |
| Thur | 171.83 |
여러 열 집계
In [277]:
tip_sum = tip.groupby('day', as_index = False)[['total_bill', 'tip']].sum()
tip_sum
Out[277]:
daytotal_billtip0123
| Fri | 325.88 | 51.96 |
| Sat | 1778.40 | 260.40 |
| Sun | 1627.16 | 247.39 |
| Thur | 1096.33 | 171.83 |
In [282]:
tip_sum = tip.groupby(['day', 'smoker'], as_index = False)[['total_bill', 'tip']].sum()
tip_sum
Out[282]:
daysmokertotal_billtip01234567
| Fri | No | 73.68 | 11.25 |
| Fri | Yes | 252.20 | 40.71 |
| Sat | No | 884.78 | 139.63 |
| Sat | Yes | 893.62 | 120.77 |
| Sun | No | 1168.88 | 180.57 |
| Sun | Yes | 458.28 | 66.82 |
| Thur | No | 770.09 | 120.32 |
| Thur | Yes | 326.24 | 51.51 |
시각화
In [210]:
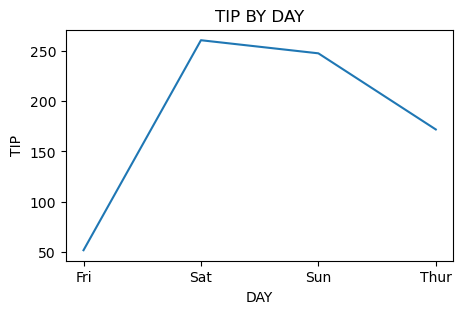
# 요일 별 팁
tip_sum = tip.groupby('day', as_index =False)[['tip']].sum()
tip_sum
Out[210]:
daytip0123
| Fri | 51.96 |
| Sat | 260.40 |
| Sun | 247.39 |
| Thur | 171.83 |
In [220]:
import matplotlib.pyplot as plt
plt.figure(figsize = (5,3))
plt.plot(tip_sum['day'], tip_sum['tip'])
plt.title('TIP BY DAY')
plt.xlabel('DAY')
plt.ylabel('TIP')
plt.show()
In [242]:
tip.loc[:, ['tip', 'total_bill']]
Out[242]:
tiptotal_bill01234...239240241242243
| 1.01 | 16.99 |
| 1.66 | 10.34 |
| 3.50 | 21.01 |
| 3.31 | 23.68 |
| 3.61 | 24.59 |
| ... | ... |
| 5.92 | 29.03 |
| 2.00 | 27.18 |
| 2.00 | 22.67 |
| 1.75 | 17.82 |
| 3.00 | 18.78 |
244 rows × 2 columns
In [285]:
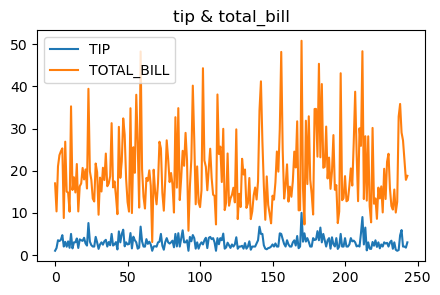
plt.figure(figsize = (5,3))
plt.plot(tip[['tip', 'total_bill']], label = ['TIP', 'TOTAL_BILL'])
plt.legend()
plt.title('tip & total_bill')
plt.show()
In [286]:
plt.figure(figsize = (5,3))
plt.bar(tip_sum['day'],tip_sum['tip'])
plt.show()
In [289]:
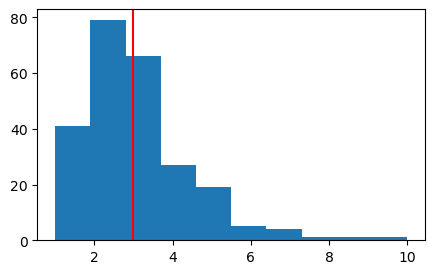
plt.figure(figsize = (5,3))
tip_mean = tip['tip'].mean()
plt.hist(tip['tip'])
plt.axvline(tip_mean, color = 'r')
plt.show()
In [291]:
plt.figure(figsize = (5,3))
plt.scatter(tip['tip'], tip['total_bill'])
plt.xlabel('TIP')
plt.ylabel('TOTAL_BILL')
plt.show()
In [ ]: