240930
복습
In [233]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats as spst
In [234]:
path = 'https://raw.githubusercontent.com/DA4BAM/dataset/master/Carseats2.csv'
data = pd.read_csv(path)
data.head()
Out[234]:
SalesCompPriceIncomeAdvertisingPopulationPriceShelveLocAgeUrbanUS01234
| 9.50 | 138 | 73 | 11 | 276 | 120 | Bad | 42 | Yes | Yes |
| 11.22 | 111 | 48 | 16 | 260 | 83 | Good | 65 | Yes | Yes |
| 10.06 | 113 | 35 | 10 | 269 | 80 | Medium | 59 | Yes | Yes |
| 7.40 | 117 | 100 | 4 | 466 | 97 | Medium | 55 | Yes | Yes |
| 4.15 | 141 | 64 | 3 | 340 | 128 | Bad | 38 | Yes | No |
숫자형 Advertising -> 숫자형 Sales
In [236]:
# 시각화
sns.scatterplot(x = 'Advertising', y = 'Sales', data = data, hue = 'US')
plt.show()

In [237]:
sns.regplot(x = 'Advertising', y = 'Sales', data = data)
plt.show()

In [238]:
sns.scatterplot(x = 'Advertising', y = 'Sales', data= data, hue = 'ShelveLoc')
plt.show()

In [239]:
# 수치화
r, pvalue = spst.pearsonr(data['Advertising'], data['Sales'])
print('r:', r)
print('pvalue:', pvalue)
r: 0.269506781376902
pvalue: 4.3776771103027514e-08
숫자형 CompPrice -> 숫자형 Sales
In [241]:
# 시각화
sns.scatterplot(x = 'CompPrice', y = 'Sales', data = data)
plt.show()

In [242]:
# 수치화
r, pvalue = spst.pearsonr(data['CompPrice'], data['Sales'])
print('r:', r)
print('pvalue:', pvalue)
r: 0.06407872955062152
pvalue: 0.2009398289418404
In [243]:
# 상관계수가 매우 작음
# what if price_diff = compPrice - Price
In [244]:
data['price_diff'] = data['CompPrice']- data['Price']
sns.regplot(x = 'price_diff', y= 'Price', data = data)
plt.show()

In [245]:
# 수치화
r, pvalue = spst.pearsonr(data['price_diff'], data['Sales'])
print('r:', r)
print('pvalue:', pvalue)
r: 0.5979217124533921
pvalue: 3.877120641788767e-40
In [246]:
# price_diff로 계산 시 강한 선형 관계 가짐
범주형 Urban -> 숫자형 Sales
In [248]:
# 시각화
sns.barplot(x = 'Urban', y = 'Sales', data = data)
plt.grid()
plt.show()

In [249]:
# 수치화 : t-test
# NaN 제거
temp = data.loc[data['Urban'].notnull()]
# 'Yes', 'No'
g1 = data.loc[temp['Urban'] == 'Yes', 'Sales']
g2 = data.loc[temp['Urban'] == 'No', 'Sales']
# t-test
t, pvalue = spst.ttest_ind(g1, g2)
print('t통계량:', t)
print('pvalue:', pvalue)
t통계량: -0.30765346670661126
pvalue: 0.7585069603942775
In [250]:
# p-value > 0.05이므로 관계없음
범주형 ShelveLoc -> 숫자형 Sales
In [252]:
# 시각화
sns.barplot(x = 'ShelveLoc', y = 'Sales', data= data)
plt.grid()
plt.show()

In [253]:
# 수치화: ANOVA
# NaN 제거
temp = data.loc[data['ShelveLoc'].notnull()]
# Bad, Good, Medium
g1 = data.loc[temp['ShelveLoc'] == 'Bad', 'Sales']
g2 = data.loc[temp['ShelveLoc'] == 'Good', 'Sales']
g3 = data.loc[temp['ShelveLoc'] == 'Medium', 'Sales']
# ANOVA
f, pvalue = spst.f_oneway(g1, g2, g3)
print('f통계량:', f)
print('pvalue:', pvalue)
f통계량: 92.22990509910346
pvalue: 1.26693609015938e-33
In [254]:
# 강한 관계
In [ ]:
이변량 범주 vs 범주
- 교차표: pd.crosstab(x, y, normalize = '?')
- 카이제곱검정
- mosaic()
- 100% Stacked Bar: df.plot.bar()
In [257]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.graphics.mosaicplot import mosaic #mosaic plot!
import scipy.stats as spst
In [258]:
titanic = pd.read_csv('https://raw.githubusercontent.com/DA4BAM/dataset/master/titanic.1.csv')
titanic.head()
Out[258]:
PassengerIdSurvivedPclassTitleSexAgeSibSpParchTicketFareCabinEmbarkedAgeGroupFamilyMotherFare201234
| 1 | 0 | 3 | Mr | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | Age_20 | 2 | 0 | 7.2500 |
| 2 | 1 | 1 | Mrs | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | Age_30 | 2 | 0 | 71.2833 |
| 3 | 1 | 3 | Miss | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | Age_20 | 1 | 0 | 7.9250 |
| 4 | 1 | 1 | Mrs | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | Age_30 | 2 | 0 | 53.1000 |
| 5 | 0 | 3 | Mr | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | Age_30 | 1 | 0 | 8.0500 |
In [259]:
# 두 범주별 빈도수를 교차표로 만들기
pd.crosstab(titanic['Sex'], titanic['Survived'])
Out[259]:
Survived01Sexfemalemale
| 81 | 233 |
| 468 | 109 |
In [260]:
# 행의 합이 1
pd.crosstab(titanic['Sex'], titanic['Survived'], normalize = 'columns')
Out[260]:
Survived01Sexfemalemale
| 0.147541 | 0.681287 |
| 0.852459 | 0.318713 |
In [261]:
# 열의 합이 1
pd.crosstab(titanic['Sex'], titanic['Survived'], normalize = 'index')
Out[261]:
Survived01Sexfemalemale
| 0.257962 | 0.742038 |
| 0.811092 | 0.188908 |
In [262]:
# 모든 합이 1
pd.crosstab(titanic['Sex'], titanic['Survived'], normalize = 'all')
Out[262]:
Survived01Sexfemalemale
| 0.090909 | 0.261504 |
| 0.525253 | 0.122334 |
In [263]:
# 시각화: Pclass별 생존여부
mosaic(titanic, ['Pclass', 'Survived'])
# 사망0, 생존1 -> titanic['Survived']의 평균은 생존율이므로 1에서 평균 빼야함
plt.axhline(1- titanic['Survived'].mean(), color = 'r')
plt.show()

In [264]:
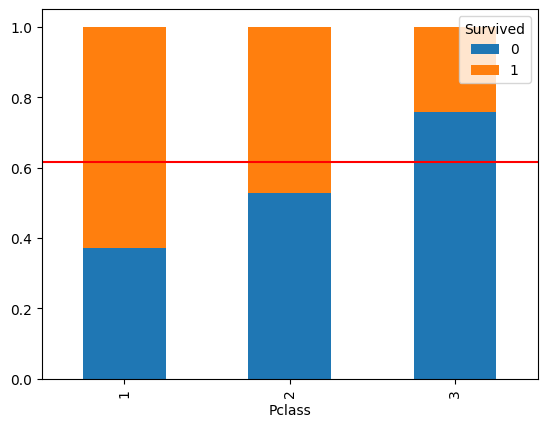
temp = pd.crosstab(titanic['Pclass'], titanic['Survived'], normalize = 'index')
print(temp)
temp.plot.bar(stacked=True)
plt.axhline(1-titanic['Survived'].mean(), color = 'r')
plt.show()
Survived 0 1
Pclass
1 0.370370 0.629630
2 0.527174 0.472826
3 0.757637 0.242363
카이제곱검정
- 범주형 변수의 자유도: 범주의 수 -1
- x변수 자유도 * y변수 자유도
- 카이제곱통계랑이 자유도의 2~3배보다 크면 차이가 있다
In [266]:
# (범주형) 객실등급 -> (범주형) 생존여부
table = pd.crosstab(titanic['Pclass'], titanic['Survived'])
table
Out[266]:
Survived01Pclass123
| 80 | 136 |
| 97 | 87 |
| 372 | 119 |
In [267]:
# 카이제곱검정
chi, pvalue, dof, frq = spst.chi2_contingency(table)
print('카이제곱통계량:', chi)
print('pvalue:', pvalue)
print('자유도:', dof)
카이제곱통계량: 102.88898875696056
pvalue: 4.549251711298793e-23
자유도: 2
In [268]:
# (범주형) Sex -> (범주형) Survived
table = pd.crosstab(titanic['Sex'], titanic['Survived'])
table
Out[268]:
Survived01Sexfemalemale
| 81 | 233 |
| 468 | 109 |
In [269]:
# 카이제곱검정
chi, pvalue, dof, frq = spst.chi2_contingency(table)
print('카이제곱통계량:', chi)
print('pvalue:', pvalue)
print('자유도:', dof)
카이제곱통계량: 260.71702016732104
pvalue: 1.1973570627755645e-58
자유도: 1
In [ ]:
이변량 숫자 vs 범주
In [271]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.graphics.mosaicplot import mosaic
import scipy.stats as spst
In [272]:
titanic = pd.read_csv('https://raw.githubusercontent.com/DA4BAM/dataset/master/titanic.1.csv')
In [273]:
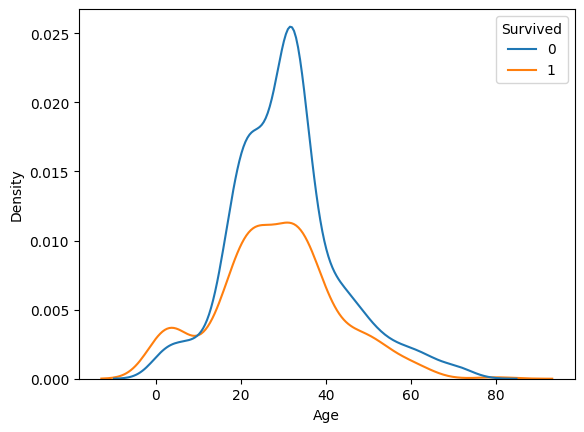
# 시각화
# (숫지) Age -> (범주) Survived
sns.histplot(x = 'Age', data = titanic, hue = 'Survived')
plt.show()

In [274]:
# default 정규화
sns.kdeplot(x = 'Age', data = titanic, hue = 'Survived')
plt.show()
In [275]:
# 정규화X
# common_norm = False
sns.kdeplot(x = 'Age', data = titanic, common_norm = False, hue = 'Survived')
plt.show()

- multiple = 'fill'
- : 곡선이 서로 겹치지 않고 각 그룹의 면적을 차지하도록
In [277]:
# multiple = 'fill'
sns.histplot(x = 'Age', data = titanic, bins = 16, hue = 'Survived', multiple = 'fill')
plt.axhline(titanic['Survived'].mean(), color = 'r')
plt.show()

In [278]:
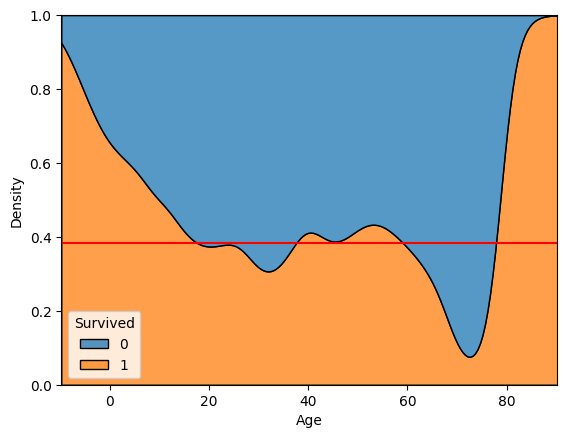
# multiple = 'fill'
sns.kdeplot(x = 'Age', data = titanic, multiple = 'fill', hue = 'Survived')
plt.axhline(titanic['Survived'].mean(), color = 'r')
plt.show()